
Yes, the headline is correct, this tutorial is about employee attrition prediction using ML algorithms.
A person like me who mostly writes tutorials on Excel and Finance has taken up this challenge to learn Data Science a few months back.
(Please note I’m a finance professional with no IT background )
And today I can confidently say I’m somewhere around the intermediate level in terms of my data science/ML skills.
So in this tutorial, I’ll show you how to predict employee attrition using various machine learning algorithms from start to end.
I think this will be a very good use case to show how we can use ML in real-world.
Employee Attrition prediction – problem statement
We have an employee dataset with features like salary, employee level, last promoted, distance from home, etc.
We also have one other field containing whether employee is with the company or left.
So based on the features we have been asked to predict how likely an employee will leave or stay with the company.
For this exercise, I have used IBM HR Analytics dataset from Kaggle.
Understanding the Attrition dataset
Here is a total list of columns that are available in our dataset, most of us can easily relate given that these are very relevant for all of us.
Lets try and understand how can we use these features to predict employee attrition.
'Age', 'Attrition', 'BusinessTravel', 'Department', 'DistanceFromHome',
'EducationField', 'EnvironmentSatisfaction', 'Gender', 'JobInvolvement',
'JobLevel', 'JobRole', 'JobSatisfaction', 'MaritalStatus',
'MonthlyIncome', 'NumCompaniesWorked', 'OverTime', 'PercentSalaryHike',
'PerformanceRating', 'RelationshipSatisfaction', 'StandardHours',
'StockOptionLevel', 'TotalWorkingYears', 'TrainingTimesLastYear',
'WorkLifeBalance', 'YearsAtCompany', 'YearsInCurrentRole',
'YearsSinceLastPromotion', 'YearsWithCurrManager'
Please note ‘Attrition‘ column is what we are trying to predict.
As you can see we have so many features.
But we may not need all of these columns for our attrition prediction so we need to apply our domain knowledge to remove some unwanted columns.
Let’s Get started
I’ve used Python & VS Code for this exercise. And please note, this is not a Data Science ‘hello world’ tutorial hence I’ll not go into detail on how to get started.
Initial steps for Employee Attrition prediction model
I have imported only a few libraries as a starting point but we will have to import other ML libraries once we have done with the EDA.
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
import numpy as np
I have now loaded Attrition CSV file into a pandas DataFrame using the below code.
df = pd.read_csv('HR-Employee-Attrition.csv')
As I mentioned before, we need to drop few columns based on our knowledge so in this case I’m dropping below columns.
But how?
For example, when we have Salary details we may not need Monthly and hourly rates, and similarly, Employee count does not add any value.
df.drop(['DailyRate','EmployeeCount','EmployeeNumber','HourlyRate',
'MonthlyRate','Over18','Education'],axis=1,inplace=True)
Now we need to make sure there are no additional spaces in our column names hence we need to use the below code to remove the blank spaces.
Its similar to TRIM formula in Excel.
df.columns = df.columns.str.strip()
One of the major headaches in any Data Science project(s) is to eliminate null values. So first we need to identify if there are any null values using the below code.
df.isna().sum()
Here is a result of the above code – as you can see there are no null values in this case.
But in reality the data will be very different.
Age 0
Attrition 0
BusinessTravel 0
Department 0
DistanceFromHome 0
EducationField 0
EnvironmentSatisfaction 0
Gender 0
JobInvolvement 0
JobLevel 0
JobRole 0
JobSatisfaction 0
MaritalStatus 0
MonthlyIncome 0
NumCompaniesWorked 0
OverTime 0
PercentSalaryHike 0
PerformanceRating 0
RelationshipSatisfaction 0
StandardHours 0
StockOptionLevel 0
TotalWorkingYears 0
TrainingTimesLastYear 0
WorkLifeBalance 0
YearsAtCompany 0
YearsInCurrentRole 0
YearsSinceLastPromotion 0
YearsWithCurrManager 0
dtype: int64
Then we can run quick info code blocks as per below to get some additional details like data types, summary statistics etc.
df.info() #quick info about fetures
df.describe() #summary statistics
Exploratory data analysis (EDA)
In this section we will use various charts to analyze data. For this I’m mainly using plotly express library as its very convenient and lot of customizations can be achieved with a simple code.
Here is simple code to generate Correlation matrix.
px.imshow(df.corr().round(2),width=1200,height=800,
color_continuous_scale='curl',aspect='auto',title='Correlation Matrix')

As you can see from the above image, Job level is highly correlated to monthly income, Total working year correlated to Monthly income, etc.
And to analyze further, I have added below Box plot to check attrition by employee level.
px.box(data_frame=df,y='JobLevel',color='Attrition',title='Attrition by level')
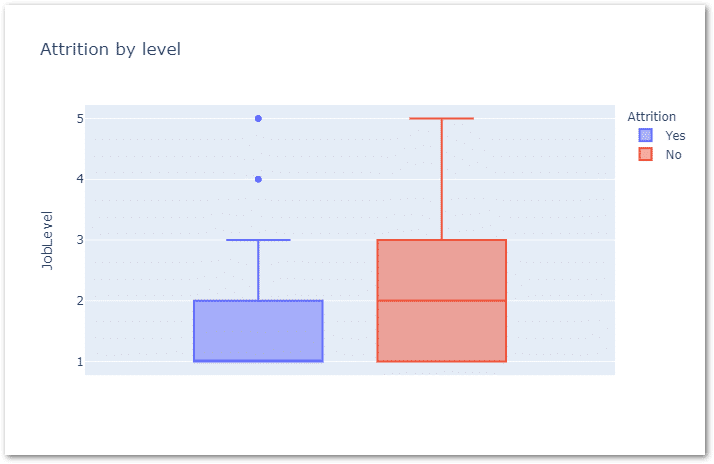
As you can see the majority of people who have left are between level 1 & level 2 and of course there are some outliers.
And next, I have compared employee salary vs attrition to identify the pattern using box plot.
px.box(data_frame=df,y='MonthlyIncome',facet_col='Attrition',
title='Monthly Income vs Attrition')
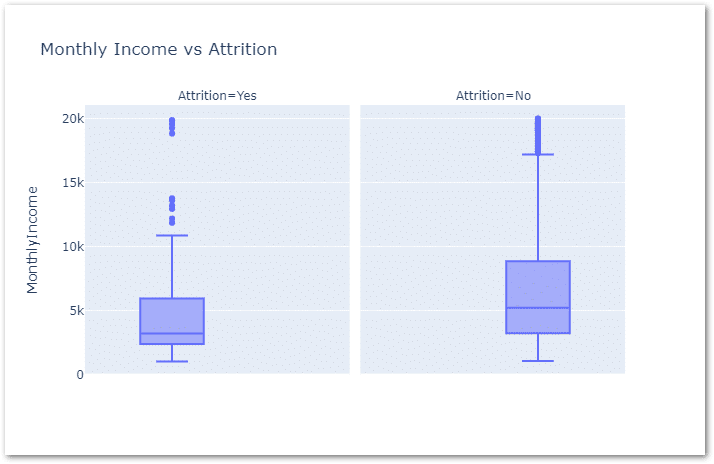
To me, it looks like most of the people who have left are underpaid and the average salary of these leavers is around $5k (+/- $1k).
Now I’d like to understand employee attrition by age group. But before that in general younger people tend to look for opportunities than elders.
Lets test this by using histogram.
px.histogram(data_frame=df,x='Age',color='Attrition',histfunc='count',
title='Attrition by Age group',barmode='relative',range_x=[15,65])
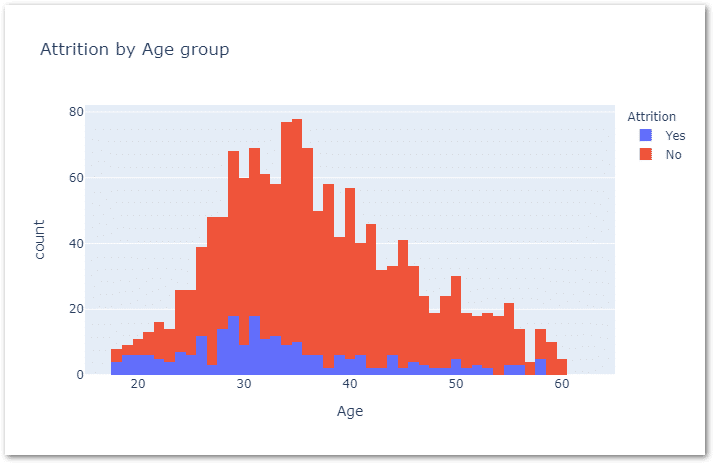
I think our domain understanding is correct, as you can see from the above most of the resignations are centered around 30 year of age.
The other factor that I’m interested in is ‘distance from home’. Because as per my understanding people don’t like to travel long distances for prolonged periods of time.
Lets check this by using box plot.
px.box(data_frame=df,x='DistanceFromHome',color='Attrition',
title='Avg distance from home',template='plotly')
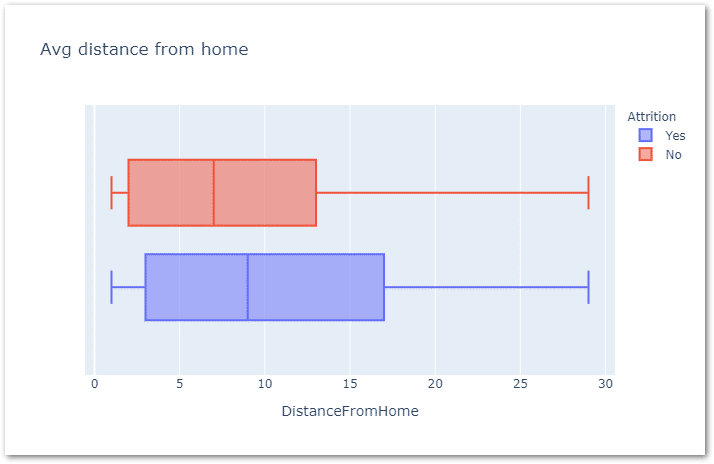
I think my assumption is correct, the higher attrition is correlated to distance based on the above.
Next lets try to understand Attrition by Marital Status, for this I’m using bar chart
px.histogram(data_frame=df,x='MaritalStatus',color='Attrition',
barmode='group',barnorm='percent',title='Attrition by Marital Status')
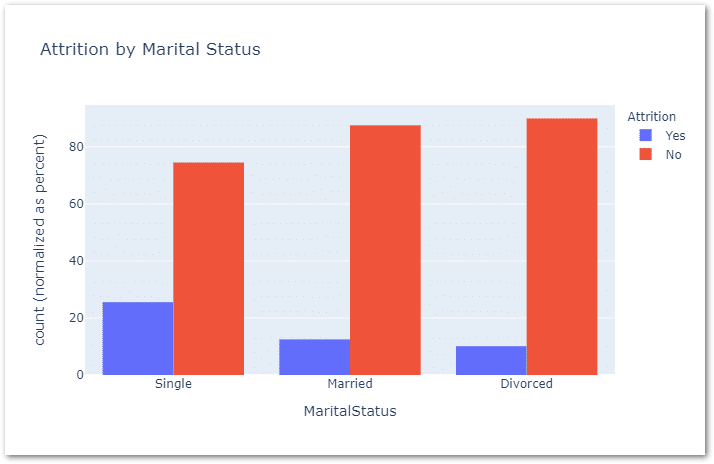
As expected, highest attrition is well correlated to ‘single’ followed by ‘Married’ & ‘Divorced’.
Now lets look at which department has the highest attrition – for this I’ll use histogram as per below.
px.histogram(data_frame=df,x='JobRole',color='Attrition',histfunc='count',
barnorm='percent',barmode='group',title='Attrition % by JobRole')
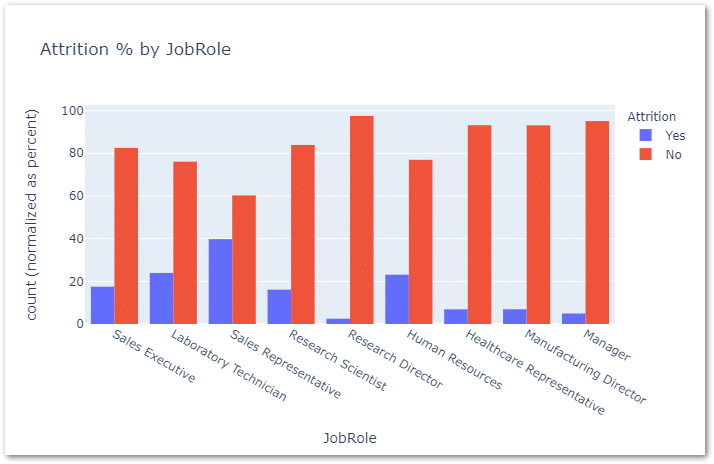
So based on this chart, the Sales department has the highest % of leavers and then followed by Lab Technician & HR, etc.
Ok, so far we have looked at various charts to explore data and understand the correlation between various features.
We can explore further (I have done it in my workbook) but for this article I’ll end EDA here.
Lets move on to next steps for predicting employee attrition.
Data Preprocessing for Machine learning models
Since we have completed our data exploration part, we now need to prepare our data for training machine learning models.
First lets split data into X & y.
In Machine learning ‘X’ means all the features, in this case Salary, Department, Level etc.
And ‘y’ means the outcome that we are trying to predict – in this case its ‘Attrition’
So I just copied our ‘df’ DataFrame and created a new DataFrame as ‘df1’ and then splits are applied as per the below code.
df1 = df.copy()
X = df1.drop(['Attrition'],axis=1) # all columns except attrition
y = df1['Attrition'] # only attrition
Importing preprocessing libraries
We need to import few more libraries to apply pre processing – please refer below.
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder,LabelEncoder, OrdinalEncoder
Please note, my preprocessing techniques are based on constructing pipeline hence its slightly different than what you normally see in YouTube.
Creating objects for all the required models as per below.
ohe = OneHotEncoder()
stScal = StandardScaler()
LEncoder = LabelEncoder()
Oencoder = OrdinalEncoder(categories=[['Single', 'Married', 'Divorced']])
Watch this video to learn more about these encoding techniques.
Using column transformer
I’m using the make_column_transformer method here to construct various preprocessing steps at once.
Here is what I’m doing in summary.
- Applying OnehotEncoder for these columns ==> OverTime’,’ Gender’, ‘BusinessTravel’, ‘Department’, ‘EducationField
- And then applying OrdinalEncoder for the ‘MaritalStatus’ column
- At the end applying StandardScaller for the ‘MonthlyIncome’ column
- No changes for all other columns
mColTransform = make_column_transformer(
(ohe['OverTime','Gender','BusinessTravel','Department','EducationField','JobRole']), # Applying OneHotEncoder
(Oencoder,['MaritalStatus']), # Applying OrdinalEncoder
(stScal,['MonthlyIncome']), # Applying standard scaller
remainder='passthrough')
I’m also applying LabelEncoder for ‘y’ to convert the text data into numerical values.
y = LEncoder.fit_transform(y)
Splitting data into training and test data
I’m now splitting our X & y data into a training set and test set to test ML model accuracy. Here is a code to do that.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
Training various ML models to predict employee attrition
Of course, this is the main part where we train three to four ML libraries for employee attrition prediction.
In this step, I’m importing quite a few ML libraries to test and pick the best model with the highest score.
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
import xgboost as xgb
from sklearn.svm import SVC
Next we need to create instances of each ML algorithm to for training and testing.
DTree = DecisionTreeClassifier()
RForecast = RandomForestClassifier()
LReg = LogisticRegression()
XGB_model = xgb.XGBClassifier(n_estimators=60, max_depth=3)
svc = SVC(kernel='linear',C=1)
Cross validation – Random forest model
I’m using Random Forecast ML algorithm to train our first model.
Now let’s create make pipeline instance and input the required arguments. In this case, the first argument is ‘column transformer‘ and next is which ML model that you want to test.
pipe = make_pipeline(mColTransform,RForecast)
I’m now using cross_val_score to test our attrition model performance as per below.
Watch this video to learn more about cross_val_score.
cross_val_score(pipe, X_train,y_train,cv=5,scoring='accuracy').mean()
This is the score that I’m getting based on current parameters for Random Forest model.
0.864784039489922
Lets start model training
Now that we know our model construction mechanism is working fine with the column transformer & make pipeline let’s quickly move on and train the model.
For that we need to use below code.
pipe.fit(X_train,y_train)
pipe.score(X_test,y_test)
0.8342391304347826
Score varies due to random changes in train test split.
Assess model performance using confusion matrix
A confusion matrix is one other way of measuring an ML model performance but it’s a little bit detailed.
Here is chart for the above model.
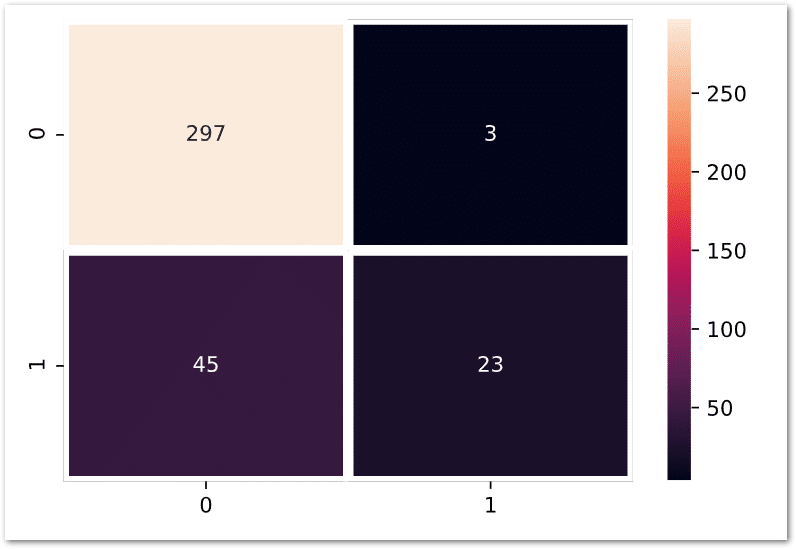
I know its bit confusing so let me interpret.
In general column reference i.e. 0 & 1 are actual values and the row referance of 0 & 1 are predicted values.
So if we look at the first box [light yellow] the number is 297 which means our model has predicted 297 times 0 which is correct based on the below column reference.
However, the second box has 45, meaning our model has predicted 45 times 1 but in reality, they are 0.
Same logic applies to other two boxes as well.
Overall its looking good but there is a scope for improvement.
Train with Decision Tree classifier
So far we have trained our model using the Random Forecast algorithm but let’s try few other ML algorithms to select the best models for this exercise.
Training steps remains same, since we have built our model using Pipeline and Column transformer its easy and no need to write/duplicate code.
In our make pipeline code, we just need to add different model instances, so in this case I’m adding Decision Tree as per below.
pipe = make_pipeline(mColTransform,<strong>DTree</strong>)
Then just run code onceagain.
cross_val_score(pipe, X_train,y_train,cv=5,scoring='accuracy').mean()
pipe.fit(X_train,y_train)
pipe.score(X_test,y_test)
# Decision Tree model score
0.7880434782608695
As you can see the score has gone down compared to Random forecast.
Train with Logistic Regression
Steps remain same, we just need to change model in pipe code.
pipe = make_pipeline(mColTransform,<strong>LReg</strong>)
cross_val_score(pipe, X_train,y_train,cv=5,scoring='accuracy').mean()
pipe.fit(X_train,y_train)
pipe.score(X_test,y_test)
cross_val_score(pipe, X_train,y_train,cv=5,scoring='accuracy').mean()
pipe.fit(X_train,y_train)
pipe.score(X_test,y_test)
# Logistic Regression model score
0.8831521739130435
The score is much better than Decision Tree and Random Forest models – lets try few other models.
Train with Support Vector Classifier
Lets try to predict employee attrition by using SVC classifier.
pipe = make_pipeline(mColTransform,<strong>svc</strong>)
cross_val_score(pipe, X_train,y_train,cv=5,scoring='accuracy').mean()
pipe.fit(X_train,y_train)
pipe.score(X_test,y_test)
cross_val_score(pipe, X_train,y_train,cv=5,scoring='accuracy').mean()
pipe.fit(X_train,y_train)
pipe.score(X_test,y_test)
# Support Vector Classifier model score
0.8695652173913043
The SVC model score is good, almost close to Logistic Regression.
ML Model selection for Attrition prediction
So far we have tried four models for employee attrition prediction but you can try few others.
Out of these four models we need to select one and then move on with other steps so in this case, I’d like to go with the SVC Linear kernel.
I’ve selected SVC because we can perform parameter tuning to improvise our model. But your preferences maybe be different.
Of course, there are various other steps like Parameter tuning, Feature selection, etc to improve model performance.
But I’ll stop here otherwise this article will become too long.
You can download Attrition analysis files from GitHub
Conclusion
Employee attrition prediction is not an easy task, you need to have a solid understanding of human behavior and skin in the game.
Fortunately I regularly deal with attrition problem and how it will impact on our business.
So I just give it a try with various Machine Learning models. To me, this is working great for now and I’ve personally learned a lot from this project.
I hope after reading this article you will be able to relate how Machine Learning can be used for our problems.
Lets me know If I’m missing anything or you would like to improve.