
If you are an aspiring Data Scientist then the Pandas pivot table is one of the primary tools that you must learn.
We all know how to use the excel pivot table. In fact, there are many use cases from summarizing data to performing calculations.
But as you know excel pivot table is based on a Graphical User Interface (GUI) so it’s relatively easy to learn and apply.
On the contrary Pandas pivot table is based on python code so it can be overwhelming for beginners and often your excel pivot table understanding will interfere.
In fact, I do use excel pivot table very often and I did face similar challenges when I get started.
So in this article, I’ll explain how to use the Pandas pivot table from an excel user point of view.
Pandas Pivot tbale – the basics
First, you need to have pandas installed in your environment and then you can import and start working on it as below.
import pandas as pdz
pd.pivot_table(.......)
The parameters available in a pandas pivot table:
pd.pivot_table(data, values=None, index=None, columns=None,
aggfunc='mean', fill_value=None, margins=False,
dropna=True, margins_name='All', observed=False, sort=True)
At first, these parameters appear to be confusing so let’s take a step back and start from the basic steps.
Pandas pivot table – hello world example
For this exercise, I have dummy sales data with multiple columns and rows. So we will use a pivot table functionality to summarize sales data by city.
Here is a snip of my summary:
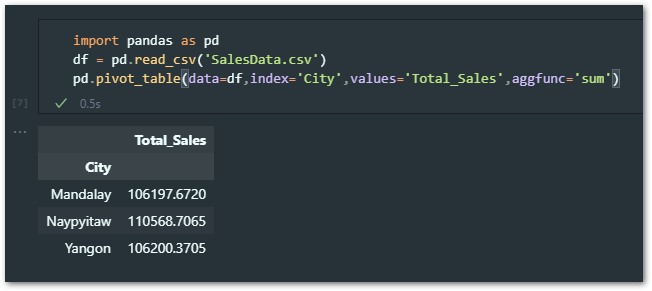
But how did I get this?
Well, first I have imported the Pandas library and then loaded the sales data CSV file into the pandas DataFrame, then I have called the Pivot table function (line one, line two & line three).
The basic parameters
We need at least four parameters to have some meaningful summary.
data: this is where you will input your DataFrame, in my case the DataFrame name was DF
index: it refers to Rows that you want to summarize, for this example I’m summarizing data by City
values: this is where you will input numerical columns, in my case its Total Sales
aggfunc: here you need to define how do you want to summarize your data, you can use basic functions like ‘sum’, ‘count’, ‘min’, ‘max’, ‘men’
Just for comparison let’s see how this would look like in excel.

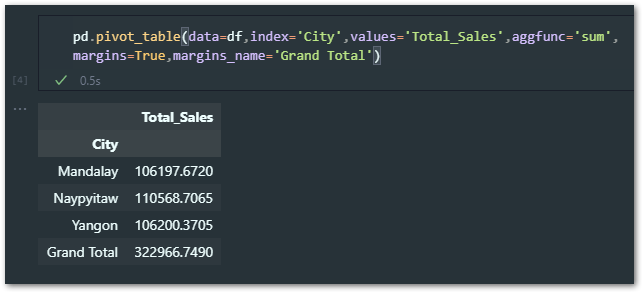
But wait…have you noticed something here..?
The excel PivotTable has the ‘Grand Total’ column but my python version does not have it, so how do we get that?
I have added two additional parameters to the code.
margins = True, margins_name = ‘Grand Total’ [you can define your own name for grand total]
pd.pivot_table(data=df,index='City',values='Total_Sales',aggfunc='sum',
margins=True,margins_name='Grand Total')
So the new summary will look like below.
So this is how we can create a basic pivot table in pandas, but there is a lot more to it.
Pandas pivot table with multiple index/rows
As you can see from the above example, we have summarized data based on the City but what if you want to add multiple columns to it.
So for this example, I’d like to summarize data by City, Gender & Product Line – this is how we can write our code.
pd.pivot_table(data=df,index=['City','Gender','Product line'],
values='Total_Sales',aggfunc='sum',
margins=True,margins_name='Grand Total')
To add multiple index’s we need to specify all our columns in a list format – so the summary looks like below.
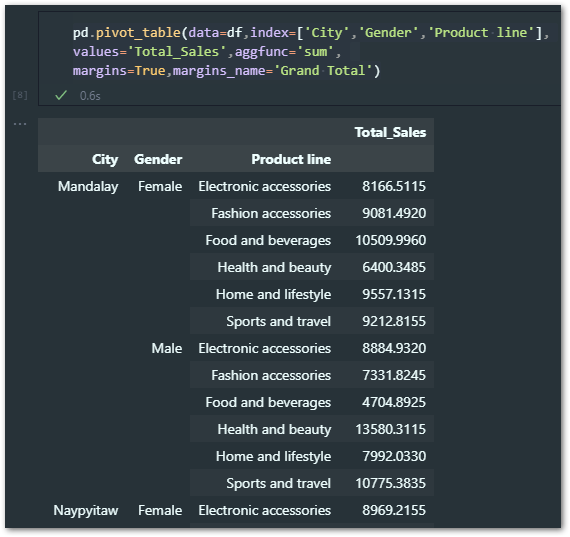
But there is one issue here i.e. the Total sales column has four decimals which is difficult to read and does not add a lot of value in this case.
So to round the numbers to zero places we can call the round function at the end of the pivot table.
pd.pivot_table(data=df,index=['City','Gender','Product line'],
values='Total_Sales',aggfunc='sum',
margins=True,margins_name='Grand Total').round()
How to add multiple value columns
Simar to the excel pivot table we can add multiple value columns to summarize data.
For this example, I’d like to summarize data by ‘Total_Sales‘, ‘Quantity‘ & ‘Gross income’ – here is how you can write the code.
Again, multiple columns should be added as a list.
pd.pivot_table(data=df,index=['City','Gender','Product line'],
values=['Quantity','Total_Sales','gross income'],
aggfunc='sum',margins=True,margins_name='Grand Total').round()
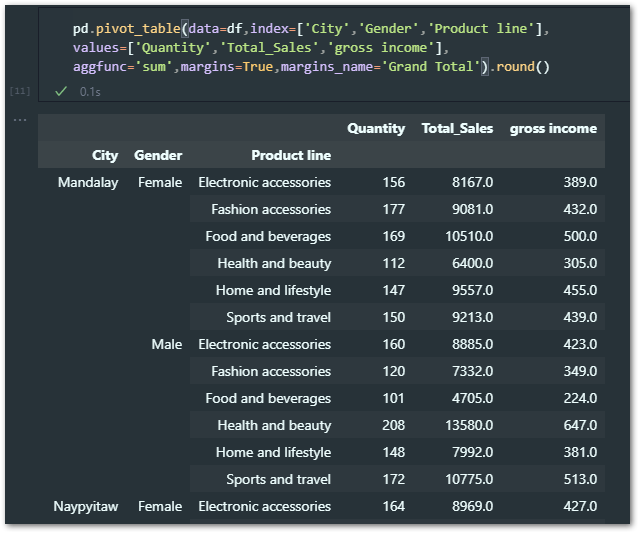
Advanced pandas pivot table
So far we have barely scratched the surface, there are much-advanced analyses that can be done with this function.
For example what if we want to run different calculations like sum, mean, count, standard deviation, etc. on our summaries.
For this example, I’d like to calculate the sum & mean of each product line. To achieve this we can write code as per below.
We can add multiple aggregation functions in a list format.
pd.pivot_table(data=df,index=['City','Gender','Product line'],
values=['Quantity','Total_Sales','gross income'],
aggfunc=['sum','mean'],
margins=True,margins_name='Grand Total').round()

This is looking good but what if you want to apply different aggregation functions for different columns?
For example, can we calculate the sum of total sales and mean of sales and quantity?
Yes, it can be done let’s give it a try.
Different aggregation functions for different columns
Once we start analyzing our data we may need to perform multiple calculations as per the requirement.
For example, you may want to know how many units were sold by each product line and what is the average sales?
Similarly, what is our Minimum, Maximum, Average & Total Sales for each product?
Here is a code to run this type of analysis using the Pandas pivot table aggfunc.
pd.pivot_table(data=df,index='Product line',
values=['Quantity','Total_Sales'],
aggfunc={'Quantity':['sum','mean'],'Total_Sales': ['min','max','sum','mean']}).round()
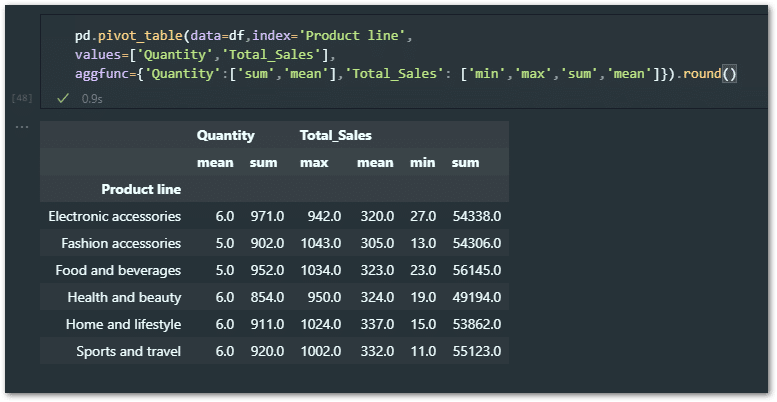
First of all, I’ve reduced complexity by removing multiple indexes, we just have ‘Product line’ now – but that doesn’t mean you can’t use multi indexes.
And then the aggfunc input values have been added using python dictionaries and lists. This way you can add multiple aggregation functions for each column.
Finally, it’s important that you remove margins/subtotals. There is some issue it seems, hence it’s throwing an error.
How to filter data in a pivot table
Very often we use filters in the excel pivot table to slice and dice the data. So the question is do we have such functionality in pandas?
The answer is yes…but is a bit complicated.
First, we need to store our pivot table in a variable and then we can apply the Pandas Query function.
In this example, I’d like to see data only for a product line ‘Sports and travel’ – this is how we can write.
First store pivot table in a variable called sales_table.
sales_table = pd.pivot_table(data=df,index='Product line',
values=['Quantity','Total_Sales'],
aggfunc={'Quantity':['sum','mean'],'Total_Sales': ['min','max','sum','mean']}).round()
Then apply pandas query function as per below.
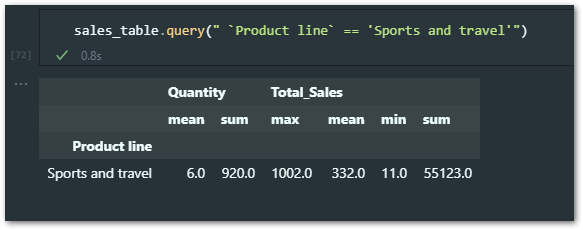
But there is a catch here, the Pandas query function works well with column names without any spaces. In this case, my column name is “Product Line” so I have a space between ‘Product and ‘Line’
This will throw an error, so to overcome this we have two options:
- You can replace blank space between column names with something like ‘_’
- Without making any changes you can use backticks in your query [if you notice the above screenshot the product line is enclosed between backticks]
Also read: Attrition prediction with ML
How to add Multiple filters
Of course, you can add multiple filters to extract information that you want by using AND function, here is a simple code.
Please note, I have now added City to the index.
sales_table.query(" `Product line` == 'Sports and travel' & City == 'Yangon' ")
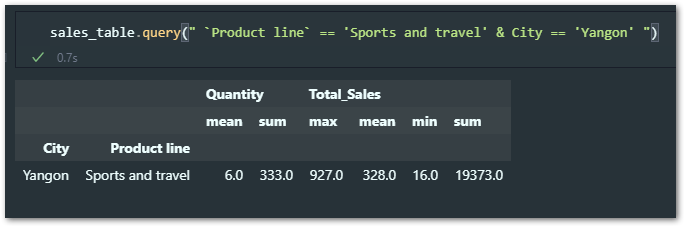
For the Pandas query function, you need to use AND symbol otherwise it won’t work.
Also, have you noticed? I have not added City within backticks because it’s just one word so no blank spaces in between.
You can also add multiple Products or cities by using a list like below.
sales_table.query(" `Product line` == ['Sports and travel','Electronic accessories'] & City == ['Yangon','Naypyitaw'] ")
The result will be like below:
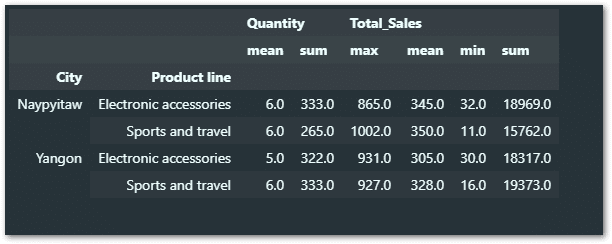
How to add More advanced filters
The above methods work great when you want to filter data that is already part of the pivot table. But if you want to filter data at a DtataFrame level?
In this example, I’ll apply three different filters using the Pandas bullion filter method.
So my conditions are:
- Branch = ‘A’
- Gender = ‘Female’
- Rating >= 5
Remember these columns are not included in our pivot, so using the below code we can filter our DataFrame.
df1 = df.copy()
df1 = df1[ (df1['Branch'] == 'A') & (df1['Gender'] == 'Female') & (df1['Rating'] >= 5)]
And then apply pivot table using the new DataFrame i.e. df1
pd.pivot_table(data=df1,
index='Product line',
values=['Total_Sales','Quantity'],
aggfunc='sum',
margins=True,
margins_name='Total').round()
Just to have visual confirmation, I have now included the above-filtered columns in our pivot table [not necessary – only for this excercse].
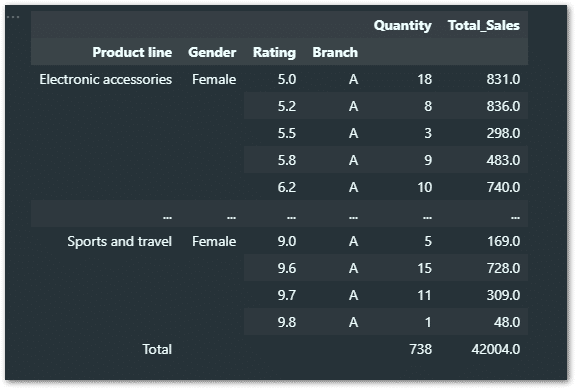
As you can see our pivot table data is now restricted as per our filters.
How to add top Columns like excel
Very often we use columns in excel pivot tables to summarize the data in 2D view which is definitely very useful and I often use it for my daily work.
Here is a summary of my excel pivot table and I’d like to have a similar view in pandas as well.
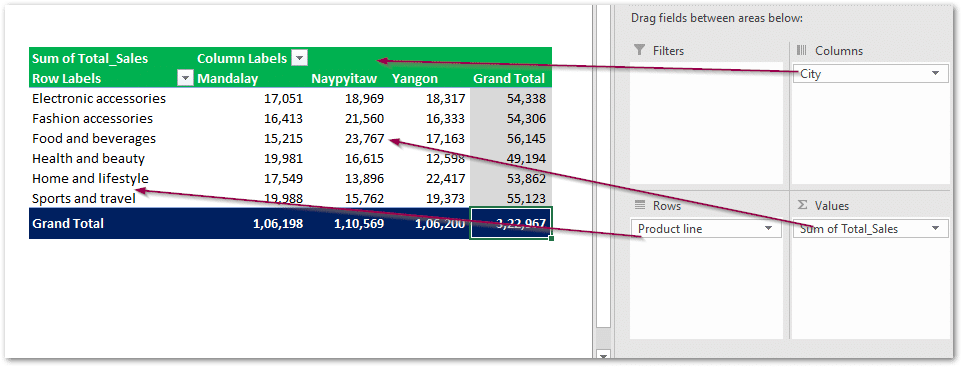
This can be achieved by defining additional parameters i.e. ‘columns’ – here is a simple code.
pd.pivot_table(data = df,
index ='Product line',
columns = 'City',
values ='Total_Sales',
aggfunc ='sum',
margins =True,
margins_name ='Total').round()
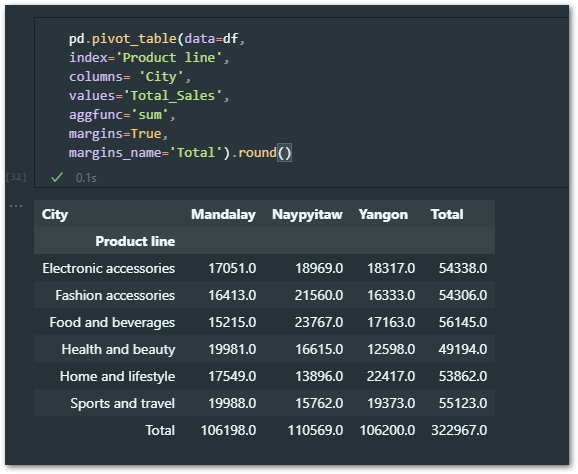
I have made a few changes i.e. Margin & Margin Name included to have subtotals for both Rows & Columns and aggfunc set it to ‘sum’.
The calculated field in Pandas pivot table
Calculated fields are well-known features in excel, I use them regularly for all my analysis. So naturally, I’d like to use similar functionality in Pandas pivotable as well.
But unfortunately, there is no built-in parameter for that but I have recently found a workaround and it works as expected.
There are two parts and here is part #1 code.
Calc_table = pd.pivot_table(data=df,
index='Product line',
values=['Total_Sales','Quantity'],
aggfunc='sum',
margins=True,
margins_name='Total').round()
I have made a few changes to the parameters i.e. ‘Total Sales’ & ‘Quantity’ added as values parameters and margins are also included.
In addition, I’ve stored this table in the ‘Calc_table’ variable.
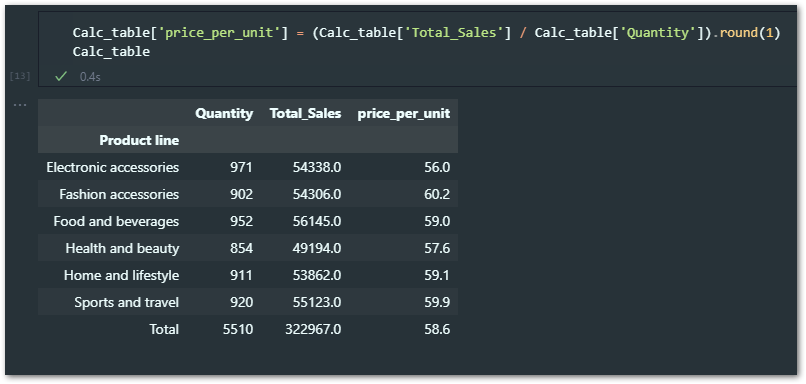
Now you need to write part #2 code to add a calculated field.
Calc_table['price_per_unit'] = (Calc_table['Total_Sales'] / Calc_table['Quantity']).round(1)
Just to explain, first I’ve created a new column and named it ‘ price_per_unit ‘ and then I’ve added calculation by accessing the ‘Calc_table’ variable and its columns like above.
In simple terms, I’ve divided the Total Sales by Quantity to get the Price per unit.
How to add Complex calculated fields
The above example is simple and useful but the real world is not that simple. We may need to apply multiple types of calculations.
So for this example, I’d like to calculate the Commission amount based on certain thresholds like below.
Commission threshold
Sales 0 – 10000 = 0%
Sales 10000 – 15000 = 5%
Sales 15000 – 20000 = 10%
Sales > 20000 = 12%
Since this problem will have multiple conditions so I have created a simple python function like below:
def comm_cal(sales):
if sales <10000:
return sales * 0.0
elif (sales >=10000) & (sales <15000):
return sales * 0.05
elif (sales >=15000) & (sales <20000):
return sales * 0.10
elif sales >=20000:
return sales * 0.12
Also, I have made a few changes to our pivot table and stored it in a new variable called Comm_table.
Comm_table = pd.pivot_table(data=df,
index=['Branch','Product line'],
values=['Total_Sales','Quantity'],
aggfunc='sum',
margins=True,
margins_name='Total').round()
Now I have applied our comm_cal function to create a separate calculated field like below.
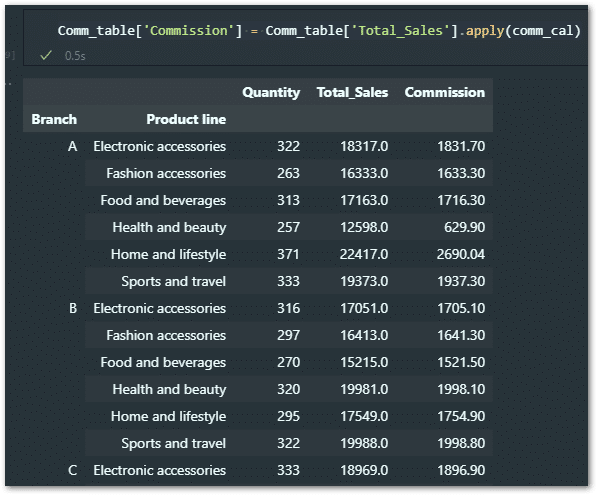
Comm_table['Commission'] = Comm_table['Total_Sales'].apply(comm_cal)
And the final result will be like is:
How to convert Pivot table into dataframe
There are many cases where you want to convert your pivot table into a Pandas DataFrame to run further analysis.
You can achieve this using a pandas built-in method called ‘to_records‘ – here is a simple code.
final_df = pd.DataFrame(Comm_table.to_records())
The main advantage of using to_records is to fill all the blanks so that we will have a nice DataFrame to further work on. Here is a reference image.

How to export Pandas pivot table
It totally depends on how do you want to use this data. There are multiple ways like Excel, CSV, HTML, JSON, etc.
But before you export, please make sure you have converted your table into records and store it in a new variable [as explained above].
Here are various code samples for various file types. After you execute this code the exported files will be available in the current project folder.
# Pandas Pivot table to CSV file
final_df.to_csv('SalesDF.csv',index=False)
# Pandas Pivot table to Excel file
final_df.to_excel('SalesDF.xlsx',index=False)
# Pandas Pivot table to HTML file
final_df.to_html('SalesDF.html')
# Pandas Pivot table to JSON file
final_df.to_json('SalesDF.json')
Conclusion
Well, what a journey it was.
We started with a simple pivot table and slowly graduated towards advanced analysis, and finally, we have learned how to export your Pandas pivot table into various formats.
It’s important that you start applying these concepts to your real-life work otherwise you will most likely forget very soon.
You can download the Sales Data CSV file & Jupyter Notebook from GitHub.
Also read:
Reasons for Excel formulas not working
Best Excel Tips & Tricks
References:
Geeks for Geeks article
CodeBasics Pivot Table tutorial